Online skill ranking was one of the big features added to the Deluxe edition of INVERSUS and building it was uncharted territory on my part. It required a bunch of learning and is one of the systems players ask about the most so I’d like to share some behind the scenes details regarding how it works.
Rank Points and Skill Rating
From the player’s perspective, they earn and lose Rank Points (RP) while playing online. I wanted the Rank Points system to achieve two goals:
- By inspecting a player’s RP, you can tell how challenging they are. Players with a higher RP are expected to defeat players with a lower RP.
- You are awarded and deducted RP in a manner that matches your expectations. If you win, your RP should increase. If you lose your RP should decrease.
While those goals might not sound like anything special, they can actually conflict because computing a statistically accurate skill rating (the first goal) can produce results which are both confusing and do not match player expectations (the second goal).
- There might be wild fluctuations as the system is first learning how you perform.
- There might be counterintuitive ups and downs such as an increase in skill after an expected due the system’s confidence level in your skill increasing more than its penalty for the match.
- You might not actually gain any skill after a win if you were expected to win.
To mitigate these issues, the actual skill rating of the player is decoupled from the player-facing representation of Rank Points. Before getting into how the Rank Points are calculated, let’s dig into the actual skill rating system they are built upon.
Computing The Skill Rating
The underlying estimation of player skill is built on top of the Glicko-2 rating system. For each player, it tracks an expected rating value, a standard deviation (i.e. how uncertain are we of the accuracy), and a volatility describing the expected fluctuation in match results. There are other rating systems out there – some of which are likely better – but I chose to build on top of Glicko-2 due to it being a freely available algorithm, and proven serviceable in prior games. Before digging into any code, I want to cover how the algorithm works at a high level and some problems it presents.
Glicko is built on the concept of rating periods. In an optimal scenario, players would have a bunch of matches across some period of time – let’s say a week – and then the full set of results is fed into the system which outputs new skill rating values. Each match finished during a rating period adjusts skill ratings based on how the match results differ from predictions. If the predictions were wrong, ratings are adjusted such that they are more likely to be correct in the future. Each completed match also increase the confidence in your skill rating accuracy while confidence also slowly decreases once per rating period. If you stop playing the game, it will grow more and more uncertain about where your skill rating lies because it doesn’t know if your time away was spent lounging or practicing. Until it regains confidence, your matches will have less of an effect on the ratings of other players.
But I don’t want rating periods!
The primary issue games are likely to have when integrating Glicko-2 is the rating period requirement. I want my skill to update immediately. I don’t want to wait until the end of the week. I might even only play the game during launch week! To solve this, I force a square beg into a round hole with the understanding that things will (more or less) work out fine. An INVERSUS rating period passes with each game played. If you play 10 games in one day and I only play 2 games, the math will have evaluate 5 times more rating periods for you than it did for me. It’s not optimal, but all the numbers still move in the right directions so life goes on.
If I stopped there, I would have a functional skill system, but I would lose the ability for uncertainty to grow due to inactivity. To prevent this issue, I also assign a period of real world time to a rating period (specifically 14 days). Every time a new match begins, I evaluate how long it has been since the prior match and process the appropriate amount of inactivity. When we get into the math, you’ll see that we can even do this for partial rating periods. INVERSUS evaluates inactivity at the granularity of 1 day. In other words, you need to stay offline for a full day before uncertainty starts to build.
UPDATE: Since writing this, I’ve had more thoughts on improving the rating period implementation which you can find here.
What about team vs team matches?
The next big problem with Glicko-2 relates to team games because it can only predict results between individual players. Once again, I bend the rules and coerce a team match through the system. Let’s consider some options for rating a 2v2 game where Alice and Alex defeat Betty and Bill.
- Individual: You can process the match results between each pair of players. Alice would update her rating by processing a victory against Betty and a victory against Bill.
- Composite Opponent: You can create a virtual opponent by averaging the skills of each player on the opposing team and then process against it. Alice would update her rating by processing a single victory against a virtual player that is the average of Betty and Bill.
- Composite Team: You can create virtual players for your team and the opposing team. You then map the result between the virtual teams back onto your own rating. Alice would update her rating based on how the Alice+Alex virtual player’s rating gets modified when processing a victory against the Betty+Bill virtual player.
According to this paper, the Composite Opponent option performed the best when evaluating 5v5 matches in SoccerBots. That said, for INVERSUS, I ended up using the Composite Team approach. My reasoning was primarily based on the user experience in some corner cases and maybe a little “gut feel”.
In a 5v5 game, one player is going to have a harder time carrying a poor team to victory. This is even more true in a game design where player perform specific role with heavy cooperation such as in soccer. In contrast, team games in INVERSUS are 2v2 and rely less on role division and cooperation between the players. Because of this, it isn’t clear that the results from the listed paper actually map well onto my game design.
To discuss a more specific scenario, let’s put you in the shoes of an amazing player. You are going to be playing a 2v2 game, with a partner chosen at random, but the opposing team is fixed. In one scenario, your teammate is very low skill; in the other scenario, your teammate is as highly skilled like you. Using the Composite Opponent method, your team composition has no bearing on the change to your rating despite the fact that you are far more likely to lose with the first teammate. This is concerning because it reinforces a negative experience when you are playing alongside a lower skill player. In contrast, the Composite Team method handles this case well. Your low skill teammate will bring the rating of your whole team down and thus reduce the expectation of a victory. As a result, any losses will have a reduced impact on your rating.
This leaves us with the question of how to actually generate the virtual players for rating purposes. INVERSUS just averages the rating and deviation values of its members (which I will cover in detail later), but I suspect there might be a more optimal approach. This optimal method might also differ from game to game. It’s possible that some game designs should weight either lower skill or higher skill players more. You might event want to weight specific roles differently such as the goalie in soccer. It might also make more sense to keep the maximum deviation value from the team instead of averaging it.
What do I really need to understand?
We’re about to take a tour through my actual Glicko-2 implementation and parts are confusing. There will be some seemingly magic numbers chosen to tune the overall system and then there’s the actual math for updating the players. Do you need to know what is actually happening? I’d say yes for some parts and no for others.
I’m the type of person that wants (or maybe even needs) to understand everything from first principles, but I also had a very pressing time constraint to get this finished fast. Having a thorough understanding of an algorithm will often let you improve upon it as you adapt it to your specific needs or even find some oversight that was missed in the original work, but in this case I only went half way with my research. On the upside, by writing my own implementation, I was able to intuit some knowledge based on how the math operations would affected the output, and this led to an improved interface for my needs. I was also able to add some numerical bounds into to system such that values would never leave a range I could store in memory, could display on screen, had tested, etc.
When first learning how Glicko-2 functions, you will find this paper: Example of the Glicko-2 system. It covers the how, but not much of the why. As I mentioned, I didn’t have the luxury of getting deep into the why, but if you want to be a better engineer than I was, you can find the paper that Glicko-2 is based on here: Dynamic paired comparison models with stochastic variances.
Why the numerical bounds?
My Glicko-2 implementation applys bounds to each player value: rating, deviation and volatility. This serves three purposes:
- Numbers are prevented from growing larger or smaller than memory supports. Limits on rating and deviation are chosen such that packing these values for transfer over the network is a safe process.
- Numbers should remain in a range that the user interface can support. While I don’t display any of these values directly, they do influence the player-facing Rank Points and I want those to live in an expected range (e.g. never negative).
- It’s nice to have a safety net when a system is this complex and you don’t claim to be an expert in its field. I did a bunch of simulated tests to make sure ratings evolved in a reasonable manner, but I was not confident in saying that things will 100% never explode due to some bug or edge case I hadn’t considered.
Technically, ratings can grow unbounded if more and more new players are allowed to enter the system and some devoted super player is always there to waiting to pounce once they build up enough skill to be fed on. In practice, that isn’t likely to ever happen. The minimum and maximum skill ratings supported by INVERSUS were chosen to compliment the state of an unrated player.
When a new player enters the system, they are given an initial expected rating, deviation and volatility. These values are chosen to imply that the player is probably average, but could also be the best player in the world or the worst. The new player is given an expected rating of μ = 0 and a standard deviation of σ = 2.015 (the Glicko recommended value). These parameters define what is called a normal distribution by using the following formula.
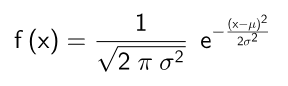
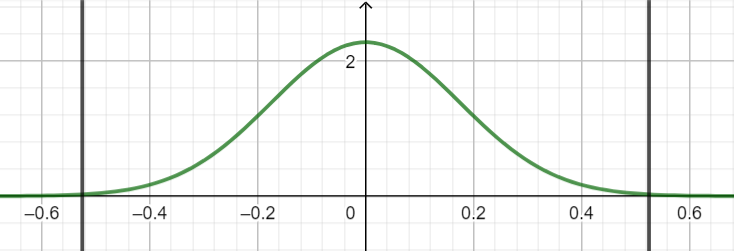
This graphs out a bell curve that can be used to evaluate the probability that a player’s skill is within a given range. To be more specific if you compute the area between two input values (the definite integral), you will get a probability. Here is the graph for the initial player settings of μ = 0 and σ = 2.015.

If μ (the expected rating) was adjusted up and down, the hump of the curve would move right and left accordingly. If σ (the standard deviation) was decreased, it would represent more confidence and the hump would raise up. In contrast, increasing σ would represent less confidence and the curve would flatten out.
To determine how likely the player’s skill is in the range of -2 to 2, you can evaluate the area under the graph within that range. In this case, it would be about 0.68 which means there is a 68% chance. If you were to evaluate between negative and positive infinity, you would get exactly 1.0 or 100% as expected.
So how does this help define minimum and maximum bounds for the rating system? If we assume that my choice of standard deviation for a new player is a good representation of the probability of any skill rating across the entire population, the curve can tell us minimum and maximum values that are highly unlikely for anyone to reach. In my case I chose the range of plus or minus 3 standard deviations which will always create a 99.7% probability. For σ = 2.015 the range is [-6.045, 6.045].

The standard deviation values themselves also get bounded. Specifically, I never let the standard deviation grow above this initial value of 2.015. The premise is that the system should never become less certain about your skill than it was initially. All this really does is limit the damage from someone leaving the game for many rating periods.
A minimum standard deviation value is used to control how much a players score can stagnate. As the deviation approaches zero and the system becomes more and more confident in a player’s skill, it will limit how much that skill changes due to a win or loss. By preventing this from ever getting too low, you can trade excitement for accuracy. Keeping this value away from zero might also help with numerical stability, but I’ve done less testing on that. INVERSUS sets it to 0.175, but I don’t recall that number being decided with any rigor. If we evaluate the normal distribution with σ = 0.175, we can see that the system will never get more than 99.7% confident in a player’s skill being 0.53 from the expected rating.
Finally, there is the choice in bounds for the volatility variable. In this case, an unranked player starts with the Glicko suggested a value of 0.06 and is never allowed to leave the range [0.04, 0.08]. The expected behavior for volatility is probably the part I understood the least so this range was chosen by looking at what numerical extents I encountered doing my simulated tests of the system. This is me saying “I don’t 100% understand this, but I’m fairly confident that things work well with in this range and I’m going to play it safe and keep it within said range”.
Glicko-2: The Interface
Let’s dig into some code! Everything is written in C++, but it is using very little of the “++” so should be easy to port to straight C if needed. I should also point out that this code uses some typedefs from my engine but should be pretty easy to follow. For example, tF64 is a 64-bit floating point value and tU32 is a 32-bit unsigned integer.
All this code is released with the following permissive zlib style license so you can just drop it into your codebase as needed.
/******************************************************************************
Copyright (c) 2018 Hypersect LLC
http://www.hypersect.com/
This software is provided 'as-is', without any express or implied
warranty. In no event will the authors be held liable for any damages
arising from the use of this software.
Permission is granted to anyone to use this software for any purpose,
including commercial applications, and to alter it and redistribute it
freely, subject to the following restrictions:
1. The origin of this software must not be misrepresented; you must not
claim that you wrote the original software. If you use this software
in a product, an acknowledgment in the product documentation would be
appreciated but is not required.
2. Altered source versions must be plainly marked as such, and must not be
misrepresented as being the original software.
3. This notice may not be removed or altered from any source
distribution.
******************************************************************************/
tGlicko2
This structure defines the constants controlling the system. You can fill this out on the stack before calling any of the functions that require it or define it once as a global variable.
//******************************************************************************
// System parameters
//******************************************************************************
struct tGlicko2
{
// Don't allow ratings to exceed these bounds.
tF64 m_minRating;
tF64 m_maxRating;
// Prevent ratings from stagnating as many games are played.
tF64 m_minDeviation;
// The initial deviation for an unrated player. A value of 2.015 is suggested.
// This also acts as the maximum deviation such that view of an inactive
// player does not become more uncertain than an unrated player.
tF64 m_unratedDeviation;
// Don't allow volatility to exceed these bounds.
tF64 m_minVolatility;
tF64 m_maxVolatility;
// The initial volatility for an unrated player. A value of 0.06 is suggested.
tF64 m_unratedVolatility;
// The system constant, tau, constrains the change in volatility over time.
// Smaller values of tau prevent the volatility measures from changing by large
// amounts, which in turn prevents enormous changes in ratings based on very
// improbable results. Reasonable choices are between 0.3 and 1.2.
tF64 m_systemConstantTau;
};
We’ve covered how I chose values for most of these parameters, but the system constant tau is new. I used a value 0.5 because it was used in an example from the Glicko-2 paper and I didn’t have the time to explore much else. Smaller values also sound safer from the description of its intent, but I wouldn’t be surprised if my choice could be improved with more experimentation.
tGlicko2_Player
Next up we have the actual representation of a player. If you are familiar with original Glicko or even Elo, you’ll know that they track ratings at a different scale than what we’ve seen in Glicko-2. In those systems, your average player is intended to have a rating of around 1500 and you can convert to and from Glicko-2 ratings with the listed equations.
//******************************************************************************
// Glicko-2 rated player.
// The rating and deviation can be converted to original Glicko units with
// the following formulas:
// glicko_rating = 172.7178*glicko2_rating + 1500
// glicko_deviation = 172.7178*glicko2_deviation
// The rating can be bounded at different confidence levels like so:
// 99.7% : rating -/+ deviation*3.000
// 99.0% : rating -/+ deviation*2.576
// 95.0% : rating -/+ deviation*1.960
// 90.0% : rating -/+ deviation*1.645
//******************************************************************************
struct tGlicko2_Player
{
tF64 m_rating; // expected rating
tF64 m_deviation; // standard deviation of rating (how uncertain we are)
tF64 m_volatility; // degree of expected fluctuation
};
tGlicko2_MatchResult
The match result structure is used to communicate the outcome of a match to the rating system. For any match, the system needs to know the opponent’s rating and deviation along with the win/loss status. This allows the algorithm to compare its win/loss predictions against the actual results. The match outcome is encoded on a real number scale where 0.0 is a loss, 0.5 is a tie and 1.0 is a victory. INVERSUS only has wins and losses, but if your game design had a less binary match result, it can be input accordingly.
//******************************************************************************
// Results of a single match against a given opponent.
//******************************************************************************
struct tGlicko2_MatchResult
{
// The opponent player rating
tF64 m_opponentRating;
tF64 m_opponentDeviation;
// The result of the match.
// 0.0 = lost to opponent
// 0.5 = tied with opponent
// 1.0 = defeated opponent
tF64 m_score;
};
Glicko2_UnratedPlayer
This function returns a player structure initialized to the appropriate settings for first entering the system. The internals aren’t complicated, but it keeps the code clean.
//****************************************************************************** // Returns a player initialized to an unrated state; //****************************************************************************** tGlicko2_Player Glicko2_UnratedPlayer(const tGlicko2& glicko);
Glicko2_ApplyInactiveRatingPeriods
This function is a helper method to compute a new player state after a period of inactivity. The implementation is O(1) compared to the O(n) solution of actually evaluating n individual rating periods. It also allows applying partial inactive rating periods!
//******************************************************************************
// Returns the new player state after a period of inactivity has passed. This
// will increase the rating deviation (i.e. the uncertainty) over time without
// adjusting the rating or volatility.
//******************************************************************************
tGlicko2_Player Glicko2_ApplyInactiveRatingPeriods(
const tGlicko2& glicko, // system parameters
const tGlicko2_Player& player, // player that is being updated
tF64 duration); // number of rating periods worth of inactivity
Glicko2_ApplyActiveRatingPeriod
This function contains the meat of the system. While it supports evaluating a full set of match results, INVERSUS only ever sends one at a time.
//******************************************************************************
// Returns the new player state given a set of match results that occured over
// one rating period. In the case of no match results being applied, this
// function is equivalent to calling Glicko2_ApplyInavtiveRatingPeriod with
// a duration of one.
//******************************************************************************
tGlicko2_Player Glicko2_ApplyActiveRatingPeriod(
const tGlicko2& glicko, // system parameters
const tGlicko2_Player& player, // player that is being updated
const tGlicko2_MatchResult* pMatchResults, // match results to evaluate
tU32 matchCount); // number of match results
Glicko-2: The Implementation
And here is all the internal magic. It uses a few functions from my math library for computing the square root, natural logarithm and exponential functions. Plug in your own math library or the C standard lib as you see fit.
//******************************************************************************
//******************************************************************************
tGlicko2_Player Glicko2_UnratedPlayer(const tGlicko2& glicko)
{
tGlicko2_Player result;
result.m_rating = 0.0;
result.m_deviation = glicko.m_unratedDeviation;
result.m_volatility = glicko.m_unratedVolatility;
return result;
}
//******************************************************************************
//******************************************************************************
static void Glicko2_ApplyPlayerBounds(const tGlicko2& glicko, tGlicko2_Player* pPlayer)
{
pPlayer->m_rating = Math::Clamp(pPlayer->m_rating, glicko.m_minRating, glicko.m_maxRating);
pPlayer->m_deviation = Math::Clamp(pPlayer->m_deviation, glicko.m_minDeviation, glicko.m_unratedDeviation);
pPlayer->m_volatility = Math::Clamp(pPlayer->m_volatility, glicko.m_minVolatility, glicko.m_maxVolatility);
}
//******************************************************************************
//******************************************************************************
tGlicko2_Player Glicko2_ApplyInactiveRatingPeriods(
const tGlicko2& glicko, // system parameters
const tGlicko2_Player& player, // player that is being updated
tF64 duration) // number of rating periods worth of inactivity
{
// Each period of inactivity increases the deviation by:
// deviation = Sqrt(deviation^2 + volatility^2)
// Expanded out for any period of time we get:
// deviation = Sqrt(deviation^2 + duration*volatility^2)
tF64 deviation = player.m_deviation;
tF64 volatility = player.m_volatility;
tGlicko2_Player result;
result.m_rating = player.m_rating;
result.m_deviation = Math::Sqrt(deviation*deviation + duration*volatility*volatility);
result.m_volatility = volatility;
Glicko2_ApplyPlayerBounds(glicko, &result);
return result;
}
//******************************************************************************
//******************************************************************************
static tF64 Glicko2_F(tF64 x, tF64 deltaSqr, tF64 variance, tF64 varianceEstimate, tF64 a, tF64 tauSqr)
{
tF64 eX = Math::Exp(x);
tF64 temp = variance + varianceEstimate + eX;
return eX*(deltaSqr - temp) / (2.0*temp*temp) - (x-a)/tauSqr;
}
//******************************************************************************
//******************************************************************************
tGlicko2_Player Glicko2_ApplyActiveRatingPeriod(
const tGlicko2& glicko, // system parameters
const tGlicko2_Player& player, // player that is being updated
const tGlicko2_MatchResult* pMatchResults, // match results to evaluate
tU32 matchCount) // number of match results
{
if (matchCount == 0)
return Glicko2_ApplyInactiveRatingPeriods(glicko, player, 1.0);
tF64 rating = player.m_rating;
tF64 deviation = player.m_deviation;
tF64 volatility = player.m_volatility;
tF64 variance = deviation*deviation;
// Compute the estimated variance of the player's rating based on game outcomes.
// Compute the estimated improvement in rating, delta, by comparing the pre-period
// rating to the performance rating based on game outcomes.
tF64 invVarianceEstimate = 0.0;
tF64 deltaScale = 0.0;
for (tU32 matchIdx = 0; matchIdx < matchCount; ++matchIdx)
{
tF64 oppenentRating = pMatchResults->m_opponentRating;
tF64 oppenentDeviation = pMatchResults->m_opponentDeviation;
const tF64 invSqrPi = 0.10132118364233777; // 1 / pi^2
tF64 g = 1.0 / Math::Sqrt(1.0 + 3.0*oppenentDeviation*oppenentDeviation*invSqrPi);
tF64 e = 1.0 / ( 1.0 + Math::Exp(-g*(rating-oppenentRating)) );
invVarianceEstimate += g*g*e*(1.0-e);
deltaScale += g*(pMatchResults->m_score - e);
}
tF64 varianceEstimate = 1.0 / invVarianceEstimate;
tF64 delta = varianceEstimate*deltaScale;
// Compute the new volatility
tF64 newVolatility;
{
tF64 a = Math::Log(volatility*volatility);
tF64 tau = glicko.m_systemConstantTau;
tF64 tauSqr = tau*tau;
tF64 deltaSqr = delta*delta;
tF64 epsilon = 0.000001; // convergence tolerance
// Set initial bounds for iteration
tF64 A = a;
tF64 B = deltaSqr - variance - volatility;
if (B > 0.0)
{
B = Math::Log(B);
}
else
{
B = a - tau;
while ( Glicko2_F(B, deltaSqr, variance, varianceEstimate, a, tauSqr) < 0.0 )
B -= tau;
}
// Compute new volatility with numerical iteration using the Illinois algorithm
// modification of the regula falsi method.
tF64 fA = Glicko2_F(A, deltaSqr, variance, varianceEstimate, a, tauSqr);
tF64 fB = Glicko2_F(B, deltaSqr, variance, varianceEstimate, a, tauSqr);
while (Math::Abs(B-A) > epsilon)
{
tF64 C = A + (A-B)*fA/(fB-fA);
tF64 fC = Glicko2_F(C, deltaSqr, variance, varianceEstimate, a, tauSqr);
if (fC*fB < 0.0)
{
A = B;
fA = fB;
}
else
{
fA *= 0.5;
}
B = C;
fB = fC;
}
newVolatility = Math::Exp(A/2);
}
// Update the new rating deviation based on one period's worth of time elapsing
tF64 newDeviation = Math::Sqrt(variance + newVolatility*newVolatility);
// Update the rating and rating deviation according to the match results
newDeviation = 1.0 / Math::Sqrt(1.0/(newDeviation*newDeviation) + invVarianceEstimate);
tF64 newRating = rating + newDeviation*newDeviation*deltaScale;
// return the new player state
tGlicko2_Player result;
result.m_rating = newRating;
result.m_deviation = newDeviation;
result.m_volatility = newVolatility;
Glicko2_ApplyPlayerBounds(glicko, &result);
return result;
}
Player Facing Rank Points
At this point, we have a functioning rating system, but as I alluded to earlier, it isn’t the most user friendly system. I wanted to make the player facing representation appear dead simple and make the skill growth a bit more fun (for some definition of fun). The core idea is to pick a functional skill value for a player based on their skill probability distribution, remap it into a more exciting numerical range, and then slowly move towards it over time without ever going in the wrong direction. Let’s cover each of those steps in a bit more detail!
First up, I convert the normal distribution of potential skill into a single functional rating number by choosing the lower bounds of a 99.7% confidence range. If you recall from earlier this is equivalent to 3 standard deviations below the expected rating and it also matches the confidence level I used to choose the extent of legal rating values. This is no coincidence and results in the functional rating for an unranked player being equal to the minimum rating value allowed by the system!
I want the actual score that players earn and lose to be more chunky. It’s more fun to earn 30 points than 0.03627 points. To do this, I remap the the min and max rating bounds from [-6.045, 6.045] to [0,10000] and refer to this new range as Rank Points. Players start at 0 Rank Points, can theoretically reach 10000 Rank Points. It is important to recognize that the lower bound of a player’s skill distribution might actually be outside the [-6.045, 6.045] range and thus needs to be clamped to zero when converting to Rank Points. This can happen if a player has a below average expected rating and then lets their deviation grow due to a long period of inactivity. This doesn’t happen often in practice because the deviation value will constrict quickly as more games are played so I prefer the clamp at zero to squeezing one more standard deviation of values into the [0,10000] range.
The final step is key to hiding all the confusing math from the player and creating an experience that better matches expectations. Instead of snapping a player’s Rank Point value to match their functional skill, I only partially approach the desired value. INVERSUS specifically steps halfway between the current RP and the desired RP, but you could choose a lower or higher percentage to meet your needs. This helps smooth out underlying skill changes and lets players “earn” towards their actual RP over multiple games of consistent performance. The returns are diminishing, but it lets players to keep earning RP for a while even if their underlying skill isn’t increasing much. I find this to be a more agreeable experience than getting one big jump and then idling with a mind set that nothing is being gained from continued victories.
This fractional approach step helps a ton, but it doesn’t fix everything. For example, a player’s desired RP value might be far lower than their current RP value due to a period of inactivity and thus even after a victory, if left as is, the system could reduce their RP! I don’t want that to ever happen so I explicitly only allow RP to decrease on a loss and only allow it to increase on a win. I actually go one step further and always award or deduct a minimum of 1 RP unless it will step you past the upper end of your 99.7% confidence bounds or the 10000 limit. Now, every match is perceived to have some reward except for the extremely rare case where you’ve won so many matches against low skill players that you’ve climbed to the top of your skill bounds one point at a time.
On the other end of the spectrum, I also limit changes in RP to 500 points. This helps in the early period of a player’s career which is often problematic for ranking systems. When just starting out, your expected rating will be bouncing all over the board with each win and loss as the system learns more about your performance. If you recall, it is highly unlikely that anyone actually has a skill that maps to a RP of zero, but everyone also starts there. As a result, you will sit at zero RP (unranked) until your first victory at which point you move towards your desired RP. These first few wins generally get clamped to 500 point increments. This creates a buffer period in which you still get rewarded for any victory as the system actually figures out how skilled you are. I think the 500 limit ended up being slightly conservative, but it was also a pretty number so I stuck with it. I’ve been very happy with this solution in contrast to the alternate path of using a waiting period of N games before the ranking system will activate for a player.
Can it be more fun?
Because RP is built on top of the potentially non-intuitive changes from Glicko-2 and I only approach the desired RP 50% at a time, there was a concern that it might not produce enough of a bump for certain matches. If you defeat someone way above your level, I wanted to make sure you got a good boost to match your excitement! As far as I recall, I had read that Rocket League tried a similar bonus score in this scenario to make a more juicy response. INVERSUS gives the winner gets an extra RP boost based on the delta between their expected rating and the opponent’s expected rating (the centers of each probability curve). If the values are at a maximal difference (12.09 in my case) a full 250 RP is added. As the expected ratings approach equality, the bonus scales towards zero. Looking back on things, I don’t think that the bonus system is actually a net benefit. It is also a bit counter-productive to my goal of smoothing the RP increase over multiple games. If I started over, I would leave it out.
Updating Skill
There are multiple locations where ratings can be updated. Normally, this happens after a match, but I also need to handle cases where a match is prematurely aborted due to early termination from the menus, network cable disconnection or application termination. At the start of every online match, the rating and deviation information of the opponent is stored in persistent save data. If the save data already has a pending unresolved match (e.g. the player quit the game), it is evaluated as a loss before storing any new match settings. If the match ends early due to the opponent quitting, the pending match is canceled (you do not get an automatic win), but normally the match is finished by both players and it is resolved according to the win/loss result afterwards.
In order for this system to work for team games, I generate the virtual opponent before storing the rating and deviation to save data. As mentioned previously, the goal is to generate a virtual opponent that represents the skill delta between the local team and the opposing team. The relevant code looks something like this:
float localTeamRatingSum = 0.0f;
for (int i = 0; i < localTeamMemberCount; ++i)
{
localTeamRatingSum += localTeamMemberRatings[i];
}
float opposingTeamRatingSum = 0.0f;
float opposingTeamDeviationSum = 0.0f;
for (int i = 0; i < opposingTeamMemberCount; ++i)
{
opposingTeamRatingSum += opposingTeamMemberRatings[i];
opposingTeamDeviationSum += opposingTeamMemberDeviations[i];
}
float localTeamRating = localTeamRatingSum / localTeamMemberCount
float opposingTeamRating = opposingTeamRatingSum / opposingTeamMemberCount
float opposingTeamDeviation = opposingTeamDeviationSum / opposingTeamMemberCount
float virtualOpponentRating = localPlayerRating + (opposingTeamRating - localTeamRating)
float virtualOpponentDeviation = opposingTeamDeviation
Game Integration
With all the numbers functional, let’s talk a bit about how I actually use them. INVERSUS is small title with a small community and while I wanted to add online skill ranking, I did not want to split the matchmaking pool. This lead me to a design where every public online match is ranked, but changes in rank aren’t flaunted as the primary focus.
When a match starts, players get to see everyone’s skill based RP value and experience level (an alternate progression system that only increases with play).

At the end of the match players can see how their RP value changed below their experience level with the experience level being the primary visual element. Players do not see the change in their opponent’s RP. There was a small hope that this would help mitigate the negative experience of a loss because your RP drop isn’t advertised, and I also thought this would help maintain an illusion of simplicity with RP values because you couldn’t see the asymmetry in change between each player. I’m torn on whether or not hiding this actually made for a better experience.

The only other place Rank Points appear in game is the leaderboards where they are compared with friends or globally.

It’s also worth discussing how skill affects the matchmaking process. It doesn’t. For the small number of players engaged in online competitive multiplayer, just finding any match was the highest priority, but even if that wasn’t a concern, there are some merits to leaving skill out of the matchmaking process. An obvious one is reduced complexity, but a less obvious one is that it lets players experience growth by actually defeating lower ranked opponents and get exposed to the skilled play of higher ranked opponents. All in all, there were more worthwhile matchmaking issues I could spend my time on.
Results
The choice of bounds for the system has been more than sufficient for the playerbase. It caps at 10000 and no one has broken 8000. The majority of the players engaged in the online competitive mode are in the 2000 to 5000 range. Given that RP values track the lower bound of a player’s skill range, this isn’t far from expectations but I haven’t done any deep analysis.
One of the larger problems is that I don’t have a way to clean stagnant scores from the leaderboards. If you stop playing, your RP lives on forever. I think this would be best solved with a “seasons” based approach where the scores all reset, but that was out of scope. Alternatively, I could periodically force the RP values to update as a server process at which point they would track their decaying lower skill bound due to inactive rating periods, but I don’t like the prospect of players returning to the game to find an unexpected RP loss.
I’m also not sure that the inactive decay of Glicko-2 is working great with RP. Its existence is hidden behind RP, but it can make your first loss after a period of absence unexpectedly high due to RP tracking the lower bound of your skill range. The underlying purpose of the deviation increasing with inactivity is sound and it’s important to remember that pulling it out would not only affect the relevant player but also all of their opponents. As for ways to improve it, I’ve had a couple untested ideas.
- One option would be to have the speed RP tracks its desired value adjust according to the deviation instead of always being at 50%. The less certain you are of a rating, the less you move. This would potentially also remove the need for a 500 cap used in the early game because the high initial deviation would automatically slow RP increases.
- An alternate option would be to shift the tracked functional rating from the current bottom of the skill range to the tightest deviation a player has ever achieved. This would make RP values permanently less susceptible to deviation increases as a player puts enough time into the game, but not remove the actual underlying benefits of inactivity affecting how ratings are computed.
The system was well stressed during launch week (primarily on Nintendo Switch) and ranked matches still occur daily, but it is nowhere near the initial cadence. I’ve been happy with the resulting experience and Rank Points show a strong correlation with player skill. It also seems to have improved player retention over the non-Deluxe edition of the game.
6 thoughts on “The Online Skill Ranking of INVERSUS Deluxe”